GANs and Diffusions for tabular data

- Arxiv article: "Tabular GANs for uneven distribution"
- Medium post: GANs for tabular data
How to use library
- Installation:
pip install tabgan - To generate new data to train by sampling and then filtering by adversarial training
call
GANGenerator().generate_data_pipe:
from tabgan.sampler import OriginalGenerator, GANGenerator, ForestDiffusionGenerator
import pandas as pd
import numpy as np
# random input data
train = pd.DataFrame(np.random.randint(-10, 150, size=(150, 4)), columns=list("ABCD"))
target = pd.DataFrame(np.random.randint(0, 2, size=(150, 1)), columns=list("Y"))
test = pd.DataFrame(np.random.randint(0, 100, size=(100, 4)), columns=list("ABCD"))
# generate data
new_train1, new_target1 = OriginalGenerator().generate_data_pipe(train, target, test, )
new_train2, new_target2 = GANGenerator().generate_data_pipe(train, target, test, )
new_train3, new_target3 = ForestDiffusionGenerator().generate_data_pipe(train, target, test, )
# example with all params defined
new_train4, new_target4 = GANGenerator(gen_x_times=1.1, cat_cols=None,
bot_filter_quantile=0.001, top_filter_quantile=0.999, is_post_process=True,
adversarial_model_params={
"metrics": "AUC", "max_depth": 2, "max_bin": 100,
"learning_rate": 0.02, "random_state": 42, "n_estimators": 100,
}, pregeneration_frac=2, only_generated_data=False,
gen_params = {"batch_size": 500, "patience": 25, "epochs" : 500,}).generate_data_pipe(train, target,
test, deep_copy=True, only_adversarial=False, use_adversarial=True)All samplers OriginalGenerator, ForestDiffusionGenerator and GANGenerator have same input parameters.
- GANGenerator based on CTGAN
- ForestDiffusionGenerator based on Forest Diffusion
- gen_x_times: float = 1.1 - how much data to generate, output might be less because of postprocessing and adversarial filtering
- cat_cols: list = None - categorical columns
- bot_filter_quantile: float = 0.001 - bottom quantile for postprocess filtering
- top_filter_quantile: float = 0.999 - top quantile for postprocess filtering
- is_post_process: bool = True - perform or not post-filtering, if false bot_filter_quantile and top_filter_quantile ignored
- adversarial_model_params: dict params for adversarial filtering model, default values for binary task
- pregeneration_frac: float = 2 - for generataion step gen_x_times * pregeneration_frac amount of data will generated. However in postprocessing (1 + gen_x_times) % of original data will be returned
- gen_params: dict params for GAN training
For generate_data_pipe methods params:
- train_df: pd.DataFrame Train dataframe which has separate target
- target: pd.DataFrame Input target for the train dataset
- test_df: pd.DataFrame Test dataframe - newly generated train dataframe should be close to it
- deep_copy: bool = True - make copy of input files or not. If not input dataframes will be overridden
- only_adversarial: bool = False - only adversarial fitering to train dataframe will be performed
- use_adversarial: bool = True - perform or not adversarial filtering
- only_generated_data: bool = False - After generation get only newly generated, without concating input train dataframe.
- @return: -> Tuple[pd.DataFrame, pd.DataFrame] - Newly generated train dataframe and test data
Thus, you may use this library to improve your dataset quality:
def fit_predict(clf, X_train, y_train, X_test, y_test):
clf.fit(X_train, y_train)
return sklearn.metrics.roc_auc_score(y_test, clf.predict_proba(X_test)[:, 1])
dataset = sklearn.datasets.load_breast_cancer()
clf = sklearn.ensemble.RandomForestClassifier(n_estimators=25, max_depth=6)
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(
pd.DataFrame(dataset.data), pd.DataFrame(dataset.target, columns=["target"]), test_size=0.33, random_state=42)
print("initial metric", fit_predict(clf, X_train, y_train, X_test, y_test))
new_train1, new_target1 = OriginalGenerator().generate_data_pipe(X_train, y_train, X_test, )
print("OriginalGenerator metric", fit_predict(clf, new_train1, new_target1, X_test, y_test))
new_train1, new_target1 = GANGenerator().generate_data_pipe(X_train, y_train, X_test, )
print("GANGenerator metric", fit_predict(clf, new_train1, new_target1, X_test, y_test))Timeseries GAN generation TimeGAN
You can easily adjust code to generate multidimensional timeseries data. Basically it extracts days, months and year from date. Demo how to use in the example below:
import pandas as pd
import numpy as np
from tabgan.utils import get_year_mnth_dt_from_date,make_two_digit,collect_dates
from tabgan.sampler import OriginalGenerator, GANGenerator
train_size = 100
train = pd.DataFrame(
np.random.randint(-10, 150, size=(train_size, 4)), columns=list("ABCD")
)
min_date = pd.to_datetime('2019-01-01')
max_date = pd.to_datetime('2021-12-31')
d = (max_date - min_date).days + 1
train['Date'] = min_date + pd.to_timedelta(pd.np.random.randint(d, size=train_size), unit='d')
train = get_year_mnth_dt_from_date(train, 'Date')
new_train, new_target = GANGenerator(gen_x_times=1.1, cat_cols=['year'], bot_filter_quantile=0.001,
top_filter_quantile=0.999,
is_post_process=True, pregeneration_frac=2, only_generated_data=False).\
generate_data_pipe(train.drop('Date', axis=1), None,
train.drop('Date', axis=1)
)
new_train = collect_dates(new_train)Experiments
Datasets and experiment design
Running experiment
To run experiment follow these steps:
- Clone the repository. All required dataset are stored in
./Research/datafolder - Install requirements
pip install -r requirements.txt - Run all experiments
python ./Research/run_experiment.py. Run all experimentspython run_experiment.py. You may add more datasets, adjust validation type and categorical encoders. - Observe metrics across all experiment in console or in
./Research/results/fit_predict_scores.txt
Experiment design
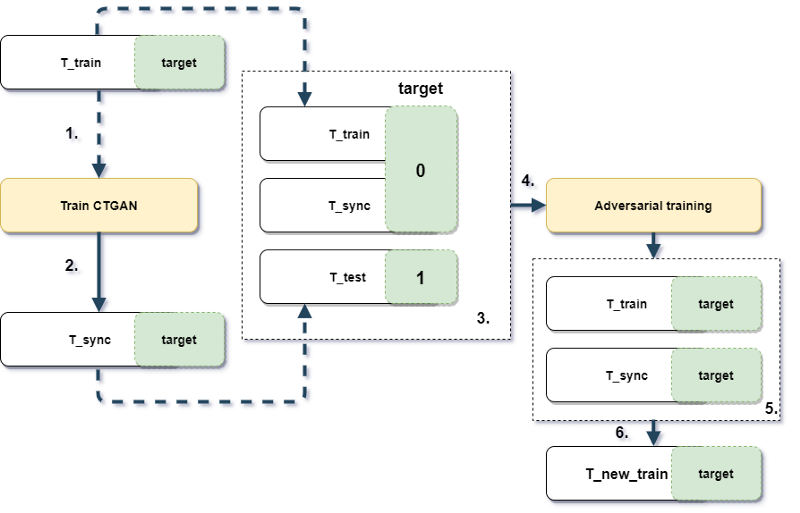
Picture 1.1 Experiment design and workflow
Results
To determine the best sampling strategy, ROC AUC scores of each dataset were scaled (min-max scale) and then averaged among the dataset.
Table 1.2 Different sampling results across the dataset, higher is better (100% - maximum per dataset ROC AUC)
| dataset_name | None | gan | sample_original |
|---|---|---|---|
| credit | 0.997 | 0.998 | 0.997 |
| employee | 0.986 | 0.966 | 0.972 |
| mortgages | 0.984 | 0.964 | 0.988 |
| poverty_A | 0.937 | 0.950 | 0.933 |
| taxi | 0.966 | 0.938 | 0.987 |
| adult | 0.995 | 0.967 | 0.998 |
Acknowledgments
The author would like to thank Open Data Science community [7] for many valuable discussions and educational help in the growing field of machine and deep learning.
Citation
If you use GAN-for-tabular-data in a scientific publication, we would appreciate references to the following BibTex entry: arxiv publication:
@misc{ashrapov2020tabular,
title={Tabular GANs for uneven distribution},
author={Insaf Ashrapov},
year={2020},
eprint={2010.00638},
archivePrefix={arXiv},
primaryClass={cs.LG}
}References
[1] Lei Xu LIDS, Kalyan Veeramachaneni. Synthesizing Tabular Data using Generative Adversarial Networks (2018). arXiv: 1811.11264v1 [cs.LG]
[2] Alexia Jolicoeur-Martineau and Kilian Fatras and Tal Kachman. Generating and Imputing Tabular Data via Diffusion and Flow-based Gradient-Boosted Trees ((2023) https://github.com/SamsungSAILMontreal/ForestDiffusion [cs.LG]
[3] Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, Kalyan Veeramachaneni. Modeling Tabular data using Conditional GAN. NeurIPS, (2019)










