Author: Vivienne DiFrancesco
A companion dashboard for exploring the data used in this project can be found here
The contents of this repository is an analysis of using machine learning models to predict depression in people using health care data. This analysis is detailed in hopes of making the work accessible and replicable.

- README.md: The top level README for reviewers of this project
- first_notebook.ipynb: Beginning narrative documentation of analysis in jupyter notebook up through the data cleaning stages
- second_notebook.ipynb: Continuation of the narriative documentation that begins after data cleaning at the explore stage of the project
- PredictingDepressionSlides.pdf: PDF version of project presentation slides
- project_functions folder: Contains the custom functions written for use in the first_notebook and second_notebook
- Dashboard folder: Folder containing files for creating the companion dashboard for this project
Millions of people globally suffer from depression and it is a debilitating condition. At best it can be difficult for people to live their lives normally and happily, and at worst it leads to death by suicide. Primary care doctors are overwhelmingly finding that they are faced with the need to treat mental health conditions such as depression without any particular training of how to handle such cases.
There is evidence that an integrated approach where physicians regularly screen patients for mental health disorders and work together with psychologists and other mental health professionals to treat patients leads to reduced costs and better patient outcomes. However, this approach can require a lot of buy-in from many individuals, require extra training, and is often not logistically feasible.
Using data from the CDC National Health and Examination Survey, machine learning was applied to predict patients who may have depression based on information that could typically be found in a medical file. These predictions could be used to put patients in touch with experienced mental health professionals sooner and easier.
The results show that 71% of those who have depression and 80% of those who don't have depression can be correctly identified. Though more work needs to be done to create a more accurate model, this shows proof of concept that this is a realistic prediction task. Better results could be yielded by adding more patient information to the data or testing more types of models.
According to the World Health Organization, more that 264 million people globally have depression. Many suicides each year are caused by depression with suicide being among the leading causes of death for young people especially.1 The National Institute of Mental Health found that the prevalence of a major depressive episode among U.S. adults in 2017 was 7.1% of people with young adults being the most affected.2
The American Psychological Association identified that primary care physicians are often being asked to diagnose mental disorders such as depression without adequate training on how to handle such treatments. According to their numbers, 70% of primary care visits are because of patients’ psychological problems, more than 80% of patients who have symptoms with no diagnosis receive psychological treatment by a physician, and only 10% follow up to a mental health professional. Patients are not getting the care they desperately need as 70% of individuals with depression go undiagnosed. Among people who commit suicide, 90% of people had a mental disorder and 40% of people had visited their doctor within the last month.3
In a study published in JAMA, doctors looked at patient outcomes, cost of care, and other factors between patients that were provided more overt diagnosing and treatment for mental health at standard doctor appointments versus patients that were not. They found that for patients that receive mental health intervention, costs went down, health care services were better utilized, patient outcomes improved, primary care doctor visits declined, treatment interventions were started earlier, and hospital and emergency care visits declined.4
The goal of this project is to gather data about people that would typically be in a patient’s medical record to predict depression.
Many clinics or doctors may find it impossible to have such integrated mental health services as cited in the previously mentioned study. Having standard services where patients are constantly screened for mental health disorders and treatment is tightly integrated with teams of physicians and psychological professionals can be expensive, requires a lot of training, requires participation from many individual doctors that may feel too overwhelmed, and may also not be possible in certain areas due to various logistical factors. Using machine learning and data that may otherwise be in a patient’s medical file, the goal is to predict who may have depression in a way that requires very little human participation from doctors and has lower time and money costs associated. The patients who are predicted to have depression could potentially be referred straight to mental health professionals in their area or who accept their health care coverage. The patient’s file could also be flagged to alert the medical staff the next time they have any kind of physician appointment to prompt doctors to start the conversation with patients. At the very least information and resources could be sent to patients directly to encourage them to take action on their own behalf.
The data for this project is from the Centers for Disease Control and Prevention National health and Nutrition Examination Survey. This data includes a vast array of health data done on a sample of the American population each year and is released every two years. The data can be found at this website: https://wwwn.cdc.gov/nchs/nhanes/default.aspx.
For this project, data was taken from the years between 2005 and 2018 and comprised of 36259 entries total of U.S. adults. Only data that was consistent across years was used and there was effort to only include data that would be reasonably found in a patient's medical file. Using as little data as possible while still being able to have accurate predictions is desirable as it would catch more people who may not have a very deep medical history and also puts less burden on providers to have to capture so much information.
The target was calculated using the PHQ-9 depression screening tool that was asked of all participants in the NHANES data. A study showed that this screening tool has a specificity and sensitivity of 88% for major depression at a threshold score of 10 or more.5 People were divided into “depressed” and “not depressed” categories based on the score for their answers in the screening tool with a score of 10 or more being “depressed”.
The approach for this project was to create many different model types to see what performs the best and to compare and contrast the different types of models. The modeling effort was done starting with simpler models and moving to more complex models. The OSEMiN process is the overarching structure of this project.
The way the data was preprocessed with feature engineering, filling missing values, and scaling was done with the goal of increasing accuracy of the models. For each type of model, a model was first trained and fitted with default parameters as a base. Then, key parameters were chosen to tune using sklearn GridSearchCV and the best parameters were used to run the model. Finally, the tuned parameters were used to fit the same model using the resampled data for comparison. Performance was compared to the base model of each type, as well as between different model types. An F-beta score was used as the scoring metric for this project and models were evaluated using a classification report, a confusion matrix, and an ROCAUC plot.
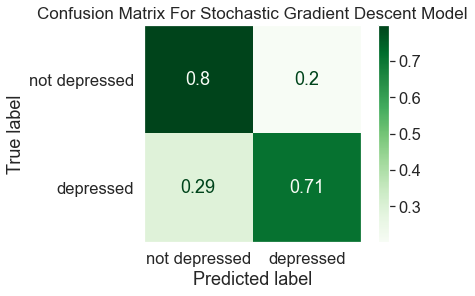
-
Overall the best model turned out to be the SGD classifier. Though many models were more accurate at classifying the not depressed class than the best model, the linear models including logistic regression, linear SVM and SGD classifier performed the best at classifying the depressed class with the stochastic gradient descent classifier being the best overall. The best model was able to accurately classify 80% of the not depressed class and 71% of the depressed class.
-
The depression class was particularly tricky to classify accurately. Pretty much every model was able to accurately identify over 80% of the true negatives. Generally the better models were at predicting the depressed class, the worse they were at predicting the not depressed class.
-
The most influencial features of the best model are shown in the chart below.
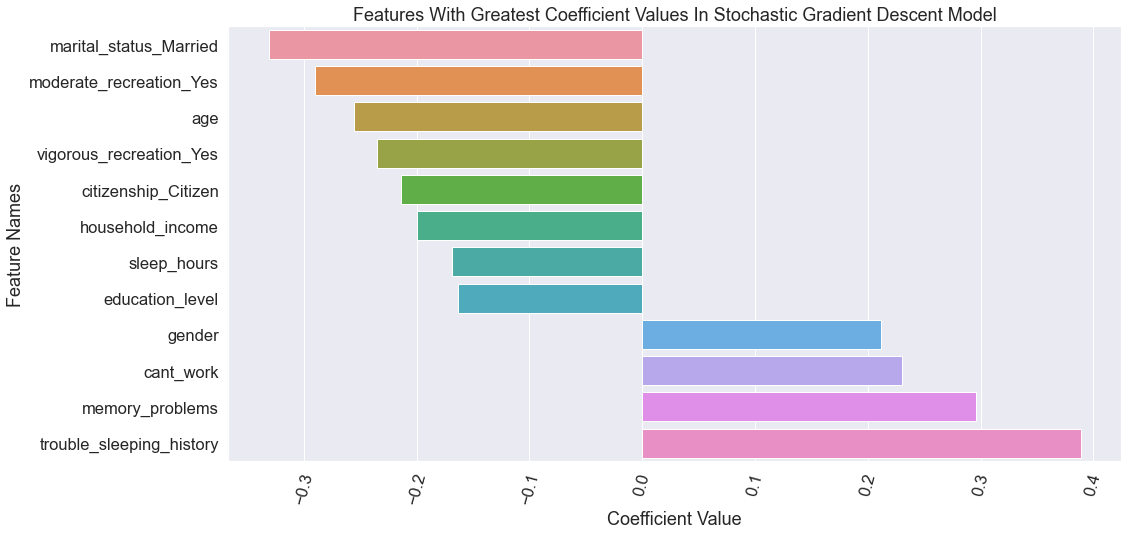
-
Health care professionals should prepare themselves to help patients with depression and can especially watch out for the most important features from the model. Right now physicians are still handling much of the first line care for patients with depression and should prepare themselves on how to better provide care for these patients. Some features that were important for the model and show a dramatic difference in those who are depressed that providers can watch for include:
- Patients who have memory problems
- Lower income, low education, and not being able to work
- Trouble sleeping and sleeping too much or too little
-
Tree based models are not the best for this task and linear models performed the best. The XGBoost classifier was the most curious as the base model was actually similar in performance to the non-tree models. But once the XGBoost model was tuned, it got worse. More tuning and experimenting could perhaps yield better results. The extra trees classifier reached results most similar to the linear models. Overall, linear models were best a classifying with this data.
-
Pick the amount of data wisely. Originally, a dataset with less features was used to model but performance of all the models was terrible. More features were added to the dataset and model performance improved enough to show some accuracy in classification. Again, more features were added with the prescription information but the model results did not improve as dramatically and greatly increased complexity. The prescription information was left in this final version of the project as users may still find it interesting to have it included with the analysis and in the companion dashboard project, but it should be noted that the line between model simplicity and model improvement can be tricky. Also, finding a way to add more patient entries instead of features may be a more appropriate way forward at this point.
-
Don't use SMOTENC or under sampling combined with SMOTENC for evening out the class distribution. It's possible other techniques/combinations of under sampling and over sampling could help modeling, but first using just SMOTENC was tried and then under sampling combined with SMOTENC was tried and both methods performed worse than the original imbalanced dataset combined with the class weight parameter. These pieces of the project were removed from the notebook narrative for brevity but it should be noted that they were attempted for the benefit of others looking to spin-off this work.
-
Everyone should prepare themselves on how to handle mental health problems and to push those they know to get proper help. Help to destigmatize mental health problems and encourage those you know to seek help from experienced professionals. Also get help for yourself if you find yourself in need of it. It's highly likely that everyone will find themselves in need of professional help at some point or another.
-
Try different models. Predicting depression is a complex and multidimensional problem so it is not surprising that it is difficult to model. Perhaps exploring more model types could reveal a strategy that was just right for this task. A neural network, for example, could open up a huge range of possibilities that have not been explored in this project. The downside of neural networks is of course the lack of transparency in what features the model is using to make predictions.
-
Add more entries and evaluate valuable features. It is desirable to get a well performing model with as little information needed about patients as possible. As mentioned earlier, modeling was attempted with less features originally and model results were terrible. Adding more features in one round improved results but adding even more features in another round after that, did not offer as much benefit while also greatly increasing complexity. An obvious opportunity in continuing this work would be to do more evaluation of features to remove those that are not helpful and perhaps experimenting if other features may be added and prove helpful. Finding the right balance between acceptable amount of error and amount of data needed to have an accurate model is definitely easier said than done. Finding a way to add more patient entries may also be valuable as there can be a lot of variation in medical histories and having more entries may better reveal complex patterns for the models to improve predictions with less features needed.
-
Testing more parameters. The depressed class was so difficult to classify that perhaps a different scoring metric could be tried like maximizing just for recall or weighting recall even more heavily in a custom F-statistic scoring object. Maybe it would be a good strategy to maximize the depressed category as much as possible and then employ strategies to improve the not depressed category as needed. There are also many combinations of parameters not tested like in the stacking and voting classifiers in particular or the XGBoost model seems like a likely place where more exploration could improve results.
-
World health Organization Depression Overview: https://www.who.int/news-room/fact-sheets/detail/depression
-
National Institute of Mental Health on Major Depression: https://www.nimh.nih.gov/health/statistics/major-depression.shtml
-
American Psychological Association Briefing Series on the Role of Psychology in Health Care: https://www.apa.org/health/briefs/primary-care.pdf
-
Association of Integrated Team-Based Care With Health Care Quality, Utilization, and Cost: https://jamanetwork.com/journals/jama/fullarticle/2545685
-
The PHQ-9: validity of a brief depression severity measure https://pubmed.ncbi.nlm.nih.gov/11556941/
-
Take the PHQ-9 depression screener online: https://www.mdcalc.com/phq-9-patient-health-questionnaire-9










