Computer Vision

"Humans use their eyes and their brains to see and visually sense the world around them. Computer vision is the science that aims to give a similar, if not better, capability to a machine or computer. Computer vision is concerned with the automatic extraction, analysis and understanding of useful information from a single image or a sequence of images" - that is the definiton google will come up with. It is pretty self explanatory. As the name suggests it gives a sense of intelligence to the vision of the machine i.e the camera.
This is the python implementation of some of the common yet important techniques often used in computer vision. Various methodologies like tracking, marking, contour drawing, feature extraction etc. are explained and implemented. Source codes are available in the repository.
Pre Requisites
Tracking

This method is used when there is a need to track any subject in a video (or a set of frames). A marker is drawn around the subject in each frame so as to identify it. The algorithm can be applied on both RGB and HSV colour spaces and the choice really depends upon the situation.
RGB colour space is useful in case of humans. We can generate and identify any colour irrespective of the difference in intensity, texture etc. But machines are not so intelligent to do so. Light blue and dark blue are completely different colours for them. Sometimes, in the RGB colour sapce, there is a difference in the colour across the same surface due to uncontrollable factors. This makes tracking an objeect very difficult.
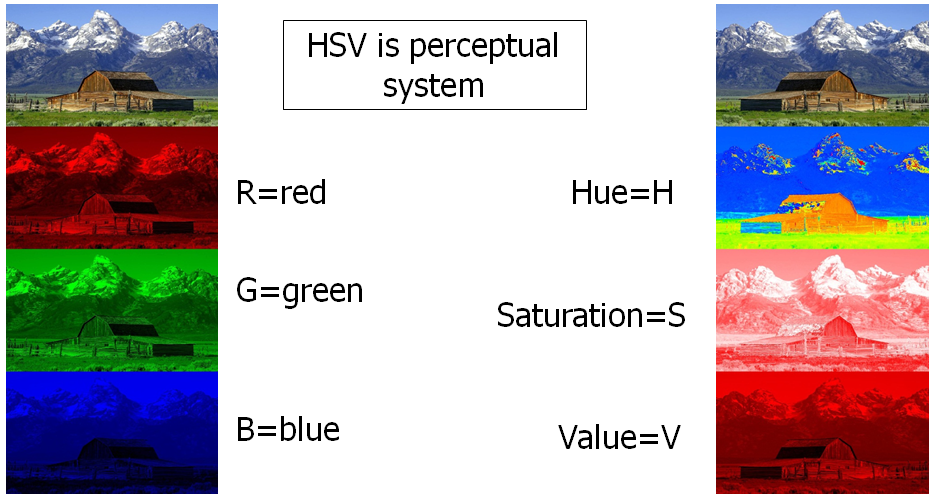
HSV colour space is muxh more efficient when it comes to identifying an object on the basis of its colour. Light blue and dark blue have the same 'Hue' value and hence it is easier to identify the colour in am image in HSV space. Here we present the method in both RGB and HSV colour sapces.
We have 2 datasets in which we have to track the red vehicle. The datasets have not been uploaded on this repository. Please feel free to ask for it.
RGB Space
In this method the red-green-blue colour channels of the images are used to detect the red vehicle. The code is written from scratch without using any libraries from OpenCV to detect the target. Basic steps followed are:
- Split the image into blue, green red channels.
- Subtract the green and blue channels from the red channel. This helps us to retain the pixels where only red colour is present. For example the white space in the original image contains all the three components. Hence, when green+blue channel is subtracted from the red channel those areas get cancelled which later can be reduced to zero by thresholding.
- Now to place the marker, get the mean point among the ones which are not reduced to zero. cv2.circle function is used to draw the circular marker. You can read more about it and other drawing functions here
Source code is here.
HSV Space
This is an another method which uses hue-saturation-value space to detect the target. This code directly uses various OpenCV libraries for thresholding. Basic steps followed are:
- Convert the colour space of the image to HSV.
- Define a range of hue values over which the image will be thresholded. Hue value of any colour can be determined by the inbuilt function of OpenCV cvtColour.
- Now to place the marker, get the mean point among the ones which are not reduced to zero.
Source code is here.
Results
Dataset 1
Original Image

Thresholded Image

Original image with the marker

Dataset 2
Original Image

Thresholded Image

Original image with the marker

Image Segmentation

In computer vision, image segmentation is the process of partitioning a digital image into multiple segments (sets of pixels, also known as super-pixels). The goal of segmentation is to simplify and/or change the representation of an image into something that is more meaningful and easier to analyze.
We'll apply a simpler version of segmentation on the image below.
The source code is here

We have to detect only the hexagons. Hence we have to segment the image such that the hexagons are separated from rest of the image. Here is the walkthrough:
- We can see that most of the part in the image is dark i.e have low pixel value except our target (hexagons) and other few places which are brighter. This gives us an advantage - segmenting the hexagons from most of the parts of the image becomes easy.
- We use thresholding method to just keep the hexagons and other brighter parts. Thresholded image looks like this:

*Thresholding parameters were fine tuned by hit and trial to get best results*- Now we have to further segregate the hexagons from the remaining parts. For this we use findContours function of OpenCV that locates all the continuous points in the image and stores them as a list of lists. Applying the same on the thresholded image we get:

- Hence we see that along with hexagons several small contours are also drawn on the image. To get rid of them, we choose only the largest 6 contours and draw them. It looks like this:

Facial Expression Recognition Using Gabor Filter

It is a type of linear filter. Special class of bandpass filters, i.e. they allow a specific range of frequencies and reject others. Gabor filters are generally used in texture analysis, edge detection, feature extraction etc. When a Gabor filter is applied to an image, it gives the highest response at edges and at points where texture changes. There are two main parameters – frequency and theta that are varied to extract the features.
Gabor filter is, hence, a feature extracting tool which is widely used in facial expression detection. The extracted features are then fed into a classifier (neural network, SVM classifier etc.) which then further trains the classifier.
Here the steps involved in feature extraction using Gabor filters (source code here is also heavily commented so that everything is clear):
- Form a filter bank of different orientations and at different scales. Mostly 40 different filters are used at 5 different scales and of 8 different orientations.

- The input image is convolved with each of the filter. So, now we have 40 different images (response matrices) corresponding to one input.
- Now, we have to extract features from each image. Several features could be used but here we have used 2:
- Local Energy - Summing up the squared values of each element of response matrix.
- Mean Amplitude - Summing up the absolute value of each element of the response matrix.
- Hence for every response matrix we have 2 values - its local energy and mean amplitude. 2 seperate matrices are formed for each value and are appended in the corresponding matrix for each response matrix. So now, we have 2 matrices of 1x40 size corrwsponding to each input image. Append one matrix to the other. This single matrix acts as the feature vector for the input image.










